Fall 2016, University of Kentucky, Models of Computation, CS 575, with Dr Goldsmith. These lecture notes are just my own, not proofread or edited by Dr G or anyone else, so they probably have lots of errors.
Last lecture we asked if you can make a bijection between and
.
We phrased it like this:
You now have a parking lot with infinite spots numbered 1, 2, 3, .... There are infinite people numbered 1, 2, 3, .... There is a bus for each possible combination (subset) of people. How can you fit every bus in your parking lot?
Answer: You can not fit them all in. No bijection exists. Why? Let’s say you fit every bus into the lot. Then let’s go down the lot and see which people are in each spot. It might look like this.
(And so on to infinity)
Now choose some people to put in a new bus. We will put person number n in our bus only if she is not in the bus in spot number n. So our bus will not have person 1 because $ 1 {1,2,3,4,5,} $. Likewise, we we will have person 2 and 3 and 5 but not person 4. So our new bus looks like B = {2,3,5,...}.
They crux move: bus B is not in any spot. It’s not in spot number 1 because that bus has person number 1 and our bus doesn’t. B isn’t in spot number 3 either because that bus doesn’t have person number 3, but B does have him. In fact, for all n, our bus B is different from the bus in the nth spot.
Hence, B is not in the parking lot at all, we forgot to park it! We broke our assumption that we fit every bus in.
If, given any random list of the subsets of $ N $, we can choose a subset that isn’t in our list, then really no good list exists. The subsets of the natural numbers are unlistable, innumerable, uncountable.
Remember that a DFA is a deterministic finite automaton, a theoretical machine that will take in a string and either accept or reject it. Look at this deterministic finite automoton. (We changed our notation a little from last notes. Now an accept state is two circles and a reject state is one circle.):
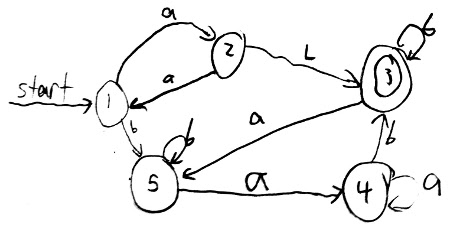
Get five people. Assign each person a different state. Each person should remember the arrows exiting her. Get a string of a’s and b’s, for example aabbabbab. Go through the string and follow the arrows. Each person calls out who goes next. All the time whoever is standing should be the current state. If the last person standing is an accept state then the string is accepted.
An NFA is a nondeterministic finite automaton. It’s like a DFA, except that one state can have multiple exiting arrows with the same letter. Also there is a thing called $ $; if state 2 has an $ $ arrow to state 3, that means whenever 2 is standing 3 must also be standing.
Look at this NFA. It is the above DFA with some extra arrows added.
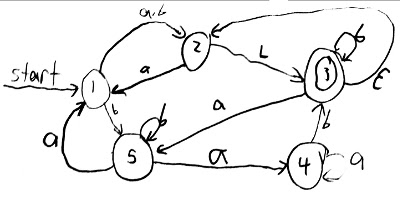
Same setup, five people, everyone remembers their exiting arrows. But now you can call out multiple next states. At any moment, you have some set of possible states standing. This is hard to keep track of. For bonus, have everyone stand on a table. If, at the end of the string, any of the standing people are an accept state, then the string is accepted. Otherwise the string is rejected.
Hopefully now you understand slightly better what a DFA is, what an NFA is, how they work, and how they are different.
In that exercise above, running the NFA was almost like running a DFA where each state was a set of standing people (instead of a state being one standing person) and the two exiting arrows (one for a and one for b) each pointed to the next set of people to be standing (instead of just pointing to the next person to stand). Check if that makes any sense in your head.
We want to show that for any NFA, there is a DFA that accepts exactly the same set of strings (the same language). We’ll prove this by giving an algorithm that can eat up an NFA and poop out an equivalent DFA.
Get ready, it’s complicated.
You give me an NFA. It has states, one of them is a start state, some number of them are accept states. There are also arrows connecting states.
Now I’ll make a DFA. First I’ll make all the states, no arrows yet. I’ll make one state for every possible subset of the states in the NFA. I’ll make the set containing only the original start state my new start state. I’ll make all the sets containing any of the original accept states my new accept states.
Now I need to connect these states with arrows. Look at a specific set S and a specific letter l. Look at all of the exiting l arrows for each of the original states in S. Collect (union) all of the destinations of these arrows into a new set T. Now add to T any states that have $ $ arrow pointing to them from a state in T. Now I draw an arrow from the set S to the set T. I do this for every letter and every set.
I am done. This constructed DFA accepts exactly the same strings as the original NFA.
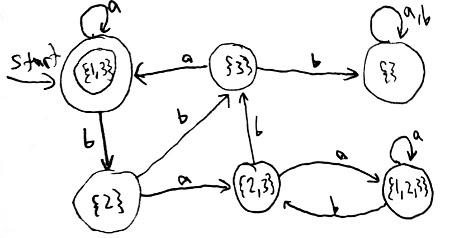
I used the algorithm to make a DFA that accepts exactly the same strings as the NFA drawn above. I omitted the subsets that are unreachable from the start state, which is why I have only 10 states instead of states.
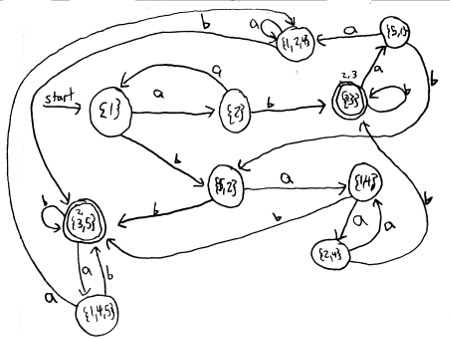
And here is that same DFA drawn as a table instead of a graph. Bold states are accept states and the italic state is the start state.
| state of DFA / | a arrow / |
b arrow |
|---|---|---|
| {1} | {2} | {2,5} |
| {2} | {1} | {2,3} |
| {1,4} | {2,4} | {2,3,5} |
| {1,5} | {1,2,4} | {2,5} |
| {2,3} | {1,5} | {2,3} |
| {2,4} | {1,4} | {2,3} |
| {2,5} | {1,4} | {2,3,5} |
| {1,2,4} | {1,2,4} | {2,3,5} |
| {1,4,5} | {1,2,4} | {2,3,5} |
| {2,3,5} | {1,4,5} | {2,3,5} |
Here is another example, taken from the book Introduction to the Theory of Computation by Michael Sipser.
A simple NFA:
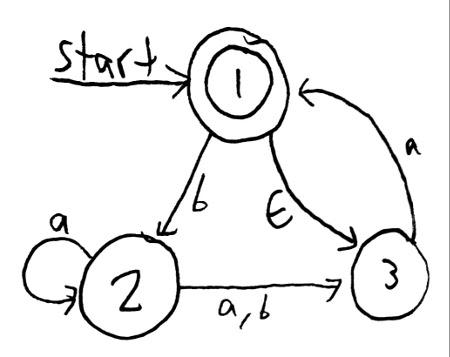
The DFA you get when you run the algorithm and take out unreachable states:
We just showed that you can convert an NFA to a DFA. Now, as an exercise, you are going to show that you can convert a regular expression to an NFA. Putting those together, we’ll know that any regular expression can be represented as a DFA.
Six parts:
l where l is a letter.r and s,r*.rs (concatenation).r+s (i.e. or, union).For 4 through 6, you can draw r and s as blobs inside your NFA.
Conclude by saying that any regular expression can be broken down into instances of the first three parts, then built back up by composing those atoms together using the last three parts. Hence, any regular expression can be drawn as an NFA and therefore a DFA.
Random sidenote. Might be useful to know later on, but mainly just for fun.
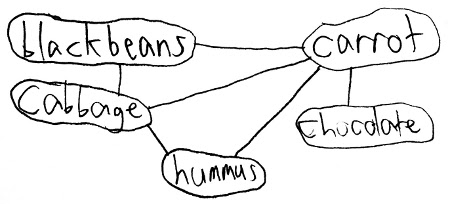
A graph is a picture, with circles usally called nodes, and lines or arrows running between them, usually called edges. We have some graphs above. Another kind of graph might have food items (blackbeans, cabbage, carrot, chocolate…) as nodes and an edge between two nodes if the two foods taste good together.
When a computer or a programmer is working with DFA’s, everything is done in tables. If the machine wants to draw it in a pretty way so that humans can easily read it, it needs to figure out where to put the nodes and edges. If you have lots of intersections of lines then the picture is hard to read, so we don’t want that. There are interesting algorithms for generating good pictures of graphs.
Some graphs are simple and you can draw them on a blackboard without having any two edges cross. This is good because it makes it easier to read. Some graphs have so many edges running between the nodes that you can’t possibly draw it on a blackboard (on a plane) without a crossing. If you can draw it without crossings, the graph is called planar. If you can’t then it’s called nonplanar.
A possibly surprising theorem: All nonplanar graphs contain at least one of the two following graphs:
Either ,

or .

And that’s lecture.
Public Domain Dedication.